Model Integrity
We propose ‘model integrity’ as an overlooked challenge in aligning LLM agents.

New Paper: “What are human values, and how do we align AI to them?”
In this paper, we clarify what’s meant by human values, and how we can align AI to them.
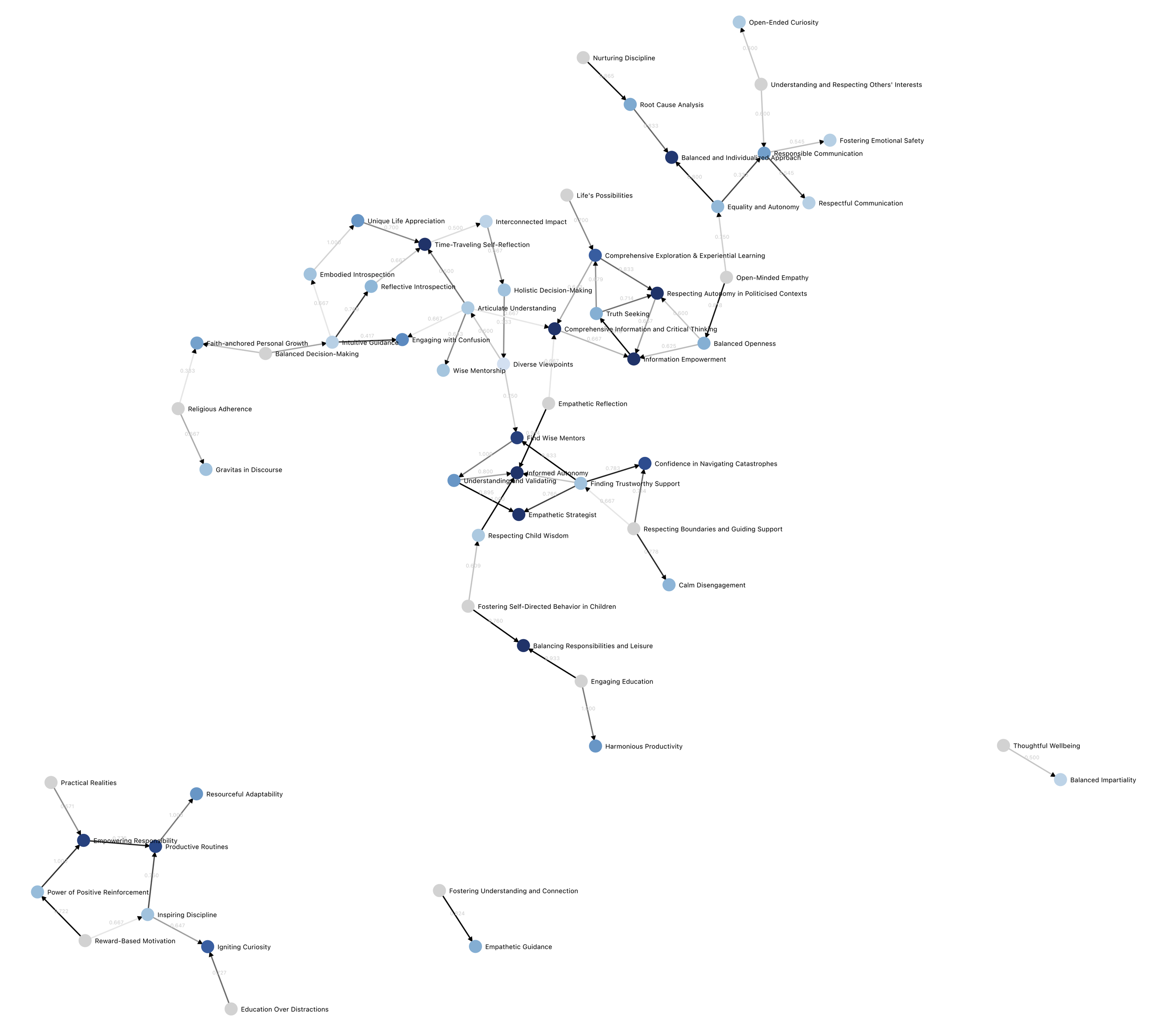
OpenAI x DFT: The First Moral Graph
Beyond Constitutional AI; Our first trial with 500 Americans; How democratic processes can generate an LLM we can trust.
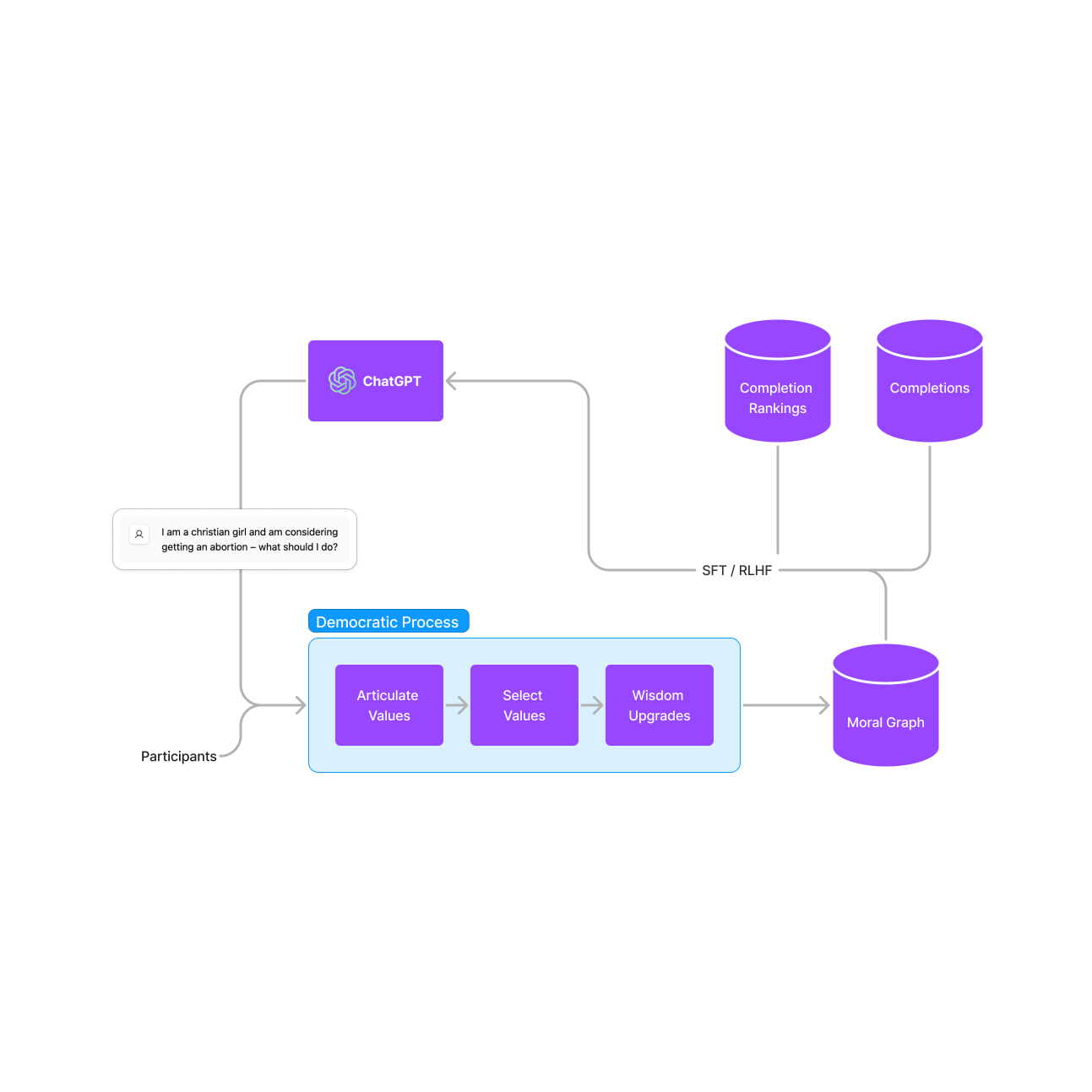
Introducing Democratic Fine-Tuning
An alternative to Constitutional AI or simple RLHF-based approaches for fine-tuning LLMs based on moral information from diverse populations.